정리 내용은 [2022 ADsP 데이터 분석 준전문가]책을 기반으로 작성하였습니다.
2022 ADsP 데이터 분석 준전문가 - 교보문고
본 도서는 한국데이터베이스진흥원에서 실시하고 있는 『데이터 분석 전문가(ADP)』 자격증과 『데이터 분석 준전문가(ADsP)』 자격증을 준비하는 수험생들을 위한 도서이다. 2014년 4월 이후 시행
www.kyobobook.co.kr
1. 분석기획 방향성 도출
1. 분석기획의 특징
분석기획
실제 분석을 수행하기 앞서 분석을 수행할 과제를 정의하고, 의도했던 결과를 도출할 수 있도록 이를 적절하게 관리할 수 있는 방안을 사전에 계획하는 일련의 작업
분석 과제 및 프로젝트를 직접 수행하는 것은 아니지만 어떠한 목표를 달성하기 위하여 어떠한 데이터를 가지고, 어떤 방식으로 수행할 지에 대한 일련의 계획을 수립하는 작업이기 때문에 성공적인 분석 결과를 도출하기 위한 중요한 작업
데이터 사이언티스트의 역량
데이터 사이언티스트는 수학/통계학적 지식 및 정보기술뿐만 아니라 해당 비즈니스에 대한 이해와 전문성을 포함한 3가지 영역에 대한 고른 역량과 시각이 요구됨
분석을 기획한다는 것은 해당 문제 영역에 대한 전문성 역량 및 수학/통계학적 지식을 활용한 분석 역량과 분석의 도구인 데이터 및 프로그래밍 기술 역량에 대한 균형 잡힌 시각을 가지고 방향성 및 계획을 수립해야 한다는 것을 의미
2. 분석대상과 방법
분석 대상과 분석 방법에 따라 4가지로 나뉜다.
특정한 분석 주제를 대상으로 진행할 경우에도, 분석 주제 및 기법의 특성상 이러한 4가지 유형을 넘나들면서 분석을 수행하고 결과를 도출하는 과정을 반복한다.
Optimization / Solution / Insight / Discovery

3. 목표 시점 별 분석 기획 방안
목표시점 별로 당면한 과제를 빠르게 해결하는 과제 중심적인 접근 방식과 지속적인 분석 내재화를 위한 장기적인 마스터플랜 방식으로 나눌 수 있다.
분석기획에서는 문제 해결을 위한 단기적인 접근방식과 분석 과제 정의를 위한 중장기적인 마스터플랜 접근방식을 융합하여 적용하는 것이 중요하다.
의미 있는 분석을 위해서는 분석 기술, IT 및 프로그래밍, 분석 주제에 대한 도메인 전문성, 의사소통이 중요하고 분석대상 및 방식에 따른 다양한 분석 주제를 과제 단위 혹은 마스터 플랜 단위로 도출할 수 있어야 한다.
| 당면한 분석 주제의 해결 (과제단위) | 지속적 분석문화 내재화 (마스터 플랜 단위) | |
| Speed & Test | 1차목표 | Accuracy & Deploy |
| Quick & Win | 과제의 유형 | Long Term View |
| Problem Solving | 접근방식 | Problem Definition |
4. 분석기획 시 고려사항

[1단계] Available Data(가용 데이터)
분석의 기본인 가용 데이터(Available Data)에 대한 고려가 필요
분석을 위한 데이터 확보가 우선적이며, 데이터의 유형에 따라 적용 가능한 솔루션 및 분석 방법이 다르기 때문에 유형에 대한 분석이 선행적으로 이루어져야 한다
Trasaction Data, Human-generated data, Mobile Data, Machine and sensor data
[2단계] Proper Business Use Case(적절한 활용방안과 유즈 케이스)
분석을 통해 가치를 창출될 수 있는 적절한 활용방안과 유즈 케이스(Proper Business Use Case) 탐색이 필요
기존에 잘 구현되어 활용되고 있는 유사분석 시나리오 및 솔루션을 최대한 활용하는 것이 중요하다.
customer analytics, Social media analytics, Plant and facility management, Pipeline management,
Price optimization, Fraud detection 등
[3단계] Low Barrier of Execution(장애 요소들에 대한 사전 계획 수립)
분석 수행 시 발생하는 장애 요소들에 대한 사전 계획 수립(Low Barrier of Execution)이 필요하다.
일회성 분석으로 그치지 않고 조직의 역량으로 내재화하기 위해서는 충분하고 계속적인 교육 및 활용방안 등의 변화 관리가 고려되어야 한다.
Cost, Simplicity, Performance, Culture 등
| 종류 | 정형데이터 | 반정형 데이터 | 비정형 데이터 |
| 설명 | Structed Data, DB로 정제된 데이터 |
Semi-structured Data, 센서 중심으로 스트리밍 된 머신데이터 | Unstructured Data, email, 보고서, 소셜미디어 데이터 |
| 특징 | 데이터 자체로 분석 가능 RDB 구조 데이터 데이터베이스로 관리 |
데이터로 분석이 가능하지만 해석이 불가능하며 메타정보를 활용해야 해석이 가능 | 데이터 자체로 분석이 불가능 특정한 처리 프로세스를 거쳐 분석데이터로 변경 후 분석 |
| 유형 | ERP, CRM, SCM 등 정보 시스템 | 로그데이터, 모바일데이터, 센싱데이터 | 영상, 음성, 문자 등 |
2. 분석 방법론
1. 분석방법론 개요
데이터 분석이 효과적으로 기업 내에 정착하기 위해서는 이를 체계화한 절차와 방법을 정리된 데이터 분석 방법론의 수립이 필수적이다.
프로젝트는 개인의 역량이나 조직의 우연한 성공에 기인해서는 안되고, 일정한 수준의 품질을 갖춘 산출물과 프로젝트의 성공 가능성을 확보하고 제시할 수 있어야 한다.
방법론은 상세한 절차, 방법, 도구와 기법, 템플릿과 산출물로 구성되어 어느 정도의 지식만 있으면 활용이 가능
데이터 기반 의사결정의 필요성
1. 경험과 감에 따른 의사결정-> 데이터 기반의 의사결정
2. 기업의 합리적인 의사결정을 가로막는 장애요소: 고정관념, 편향된 생각, 프레이밍 효과 등등
* 프레이밍 효과: 문제의 표현방식에 따라 동일한 사건이나 상황임에도 불구하고 개인의 판단이나 선택이 달라질 수 있는 현상
방법론 생성과정

암묵지: 학습과 경험을 통해 개인에게 체화되어 있지만 겉으로 드러나지 않은 지식 / 사회적으로 중요하지만 다른 사람에게 공유되기 어려움 / 공통화, 내면화
형식지: 문서나 매뉴얼처럼 형식화된 지식 / 전달과 공유가 용이함 / 표출화, 연결화
방법론 적용 업무 특성에 따른 모델
폭포수 모델: 단계를 순차적으로 진행하는 방법. 이전 단계가 완료되어야 다음 단계로 진행될 수 있으며 문제가 발견될 시 피드백 과정이 수행된다.
프로토타입 모델: 폭포수 모델의 단점을 보완하기 위해 점진적으로 시스템을 개발해 나가는 접근 방식. 고객의 요구를 완전히 이해하고 잇지 못하거나 완벽한 요구 분석의 어려움을 해결하기 위해 일부분을 우선 개발하여 사용자에게 제공. 시험 사용 후 사용자의 요구를 분석하거나 요구 정당성을 점검, 성능을 평가하여 그 결과를 통한 개선 작업을 시행하는 모델
나선형 모델: 반복을 통해 점증적으로 개발하는 방법. 처음 시도하는 프로젝트에 적용이 용이하지만 관리 체계를 효과적으로 갖추지 못한 경우 복잡도가 상승하여 프로젝트 진행이 어려울 수 있다.
방법론의 구성
단계: 최상위 계층으로서 프로세스 그룹을 통하여 완성된 단계별 산출물이 생성된다. 각 단계는 기준선으로 설정되어 관리되어야 하며, 버전 관리 등을 통해 통제된다. / 단계별 완료 보고서
테스크: 단계를 구성하는 단위 활동으로써 물리적 또는 논리적 단위로 품질 검토의 항목이 된다. / 보고서
스탭: WBS의 워크 패키지에 해당되고 입력자료, 처리 및 도구, 출력자료로 구성된 단위 프로세스이다. / 보고서 구성요소
2. KDD 분석방법론
KDD는 데이터로부터 통계적 패턴이나 지식을 찾기 위해 활용할 수 있도록 체계적으로 정리한 데이터 마이닝 프로세스이다. 데이터마이닝, 기계학습, 인공지능, 패턴인식, 데이터 시각화 등에서 응용될 수 있는 구조를 가진다.
KDD 분석 절차

데이터 셋 선택(Selection): 데이터 셋 선택에 앞서 분석 대상의 비즈니스 도메인에 대한 이해의 프로젝트 목표 설정이 필수이며 데이터베이스 또는 원시 데이터에서 분석에 필요한 데이터를 선택하는 단계. 데이터 마이닝에 필요한 목표 데이터를 구성하여 분석에 활용
데이터 전처리(Preprocessing): 추출된 분석대상용 데이터 셋에 포함되어 있는 잡음(Noise) 이상치(Outlier), 결측치(Missing Value)를 식별하고 필요시 제거하거나 의미 있는 데이터로 재처리하여 데이터 셋을 정제하는 단계. 추가로 요구되는 데이터셋이 필요한 경우 데이터 선택 프로세스 재실행
데이터 변환(Transformation): 데이터 전처리 과정을 통해 정제된 데이터에 분석 목적에 맞게 변수를 생성, 선택하고 데이터의 차원을 축소하여 효율적인 데이터 마이닝을 할 수 있도록 데이터에 변경하는 단계. 학습용 데이터와 검증용 데이터를 분리하는 관계
데이터 마이닝(Data Mining): 학습용 데이터를 이용하여 분석 목적에 맞는 데이터 마이닝 기법 선택하고, 적절한 알고리즘 적용하여 데이터 마이닝 작업을 실행하는 단계. 필요에 따라 데이터 전처리와 데이터 변환 프로세스를 추가로 실행하여 최적의 결과를 산출
데이터 마이닝 결과 평가(Interpretation/Evaluation): 데이터마이닝 결과에 대한 해석과 평가, 그리고 분석 목적과의 일치성을 확인. 데이터 마이닝을 통해 발견된 지식을 업무에 활용하기 위한 방안 마련의 단계. 필요에 따라 데이터 선택 프로세스에서 데이터 마이닝 프로세스를 반복 수행
3. CRISP-DM 분석방법론
Cross Industry Standard Process for Data Minning)의 약자. 주요한 5개 업체들(Daimler-Chrysler, SPSS, NCR, Teradata, OHA)이 주도하였으며, 계층적 프로세스 모델로써 4개의 레벨로 구성됨
CRISP-DM의 4 레벨 구조

Phases(단계): 우리가 생각하는 일반적인 단계 (ex: 기획, 수집, 분석)
Generic Tasks(일반과제): 데이터 마이닝의 단일 프로세스를 완벽하게 수행하는 단위 (ex: 데이터 정제)
Specialized Tasks(세부과제): 일반과제를 구체적으로 나눈 태스크로 데이터 정제라는 일반화 과제를 범주형/연속형 데이터 정제와 같은 태스크로 구성 가능
Process Instances(프로세스 실행) : 데이터 마이닝을 위한 구체적인 실행
CRISP-DM의 프로세스
| 단계 | 내용 & 수행업무 |
| 업무 이해 (Business Understanding) |
비즈니스 관점에서 프로젝트의 목적과 요구사항의 이해 하기 위한 단계. 도메인 지식을 데이터 분석을 위한 문제정의로 변경하고, 초기 프로젝트 계획 수립 업무 목적 파악, 상황 파악, 데이터 마이닝 목표 설정, 프로젝트 계획 수립 |
| 데이터 이해 (Data Understanding) |
분석을 위한 데이터를 수집하고 데이터 속성을 이해하기 위한 단계. 데이터 품질에 대한 문제점을 식별하고 숨겨져 있는 인사이트를 발견 초기 데이터 수집, 데이터 기술 분석, 데이터 탐색, 데이터 품질 확인 |
| 데이터 준비 (Data Preparation) |
분석을 위하여 수집된 데이터에서 분석기법에 적합한 데이터를 편성하는 단계(많은 시간 소요) 분석용 데이터 셋 선택, 데이터 정제, 분석용 데이터 셋 편성, 데이터 통합, 데이터 포맷팅 |
| 모델링 (Modeling) |
다양한 모델링기법과 알고리즘을 선택 & 모델링과정에서 사용되는 파라미터를 최적화해 나가는 단계 모델링 과정에서 데이터 셋이 추가로 필요한 경우 데이터 준비 단계를 반복 수행할 수 있으며, 모델링 데이터 결과를 테스트용 데이터 셋으로 평가하여 모델의 과적합 문제 확인 |
| 평가 (Evaluation) |
모델링 결과 가 프로젝트 목적에 부합하는지 평가하는 단계로 데이터마이닝 결과를 최종적으로 수용할 것인지 판단 분석 결과 평가, 모델링 과정 평가, 모델 적용성 평가 |
| 전개 (Deployment) |
모델링과 평가 단계를 통하여 완성된 모델을 실 업무에 적용하기 위한 계획을 수립하는 단계. 모니터링과 모델의 유지보수 계획 마련(모델이 적용되는 비즈니스 도메인 특성, 입력되는 데이터 품질 편차, 운영모델의 평가 기준에 따라 생명주기가 다양하므로 상세한 전개 계획 필요). CRISP-DM의 마지막 단계, 프로젝트 종료 관련 프로세스를 수행하여 프로젝트 마무리 전개 계획 수립, 모니터링 유지보수 계획 수립, 프로젝트 종료 보고서 작성, 프로젝트 리뷰 |
4. KDD와 CRISP-DM의 비교
| KDD | CRISP-DM |
| 분석 대상 비즈니스 이해 | 업무 이해(Business Understanding) |
| 데이터 셋 선택(Data Selection) | 데이터의 이해(Data Understanding) |
| 데이터 전처리(Preprocessing) | |
| 데이터 변환(Transformation) | 데이터준비(Data Preparation) |
| 데이터 마이닝(Data Mining) | 모델링(Modeling) |
| 데이터 마이닝 결과 평가(Interpretation/Evaluation) | 평가(Evaluation) |
| 데이터 마이닝 활용 | 전개(Deployment) |
5. 빅데이터 분석방법론
빅데이터 분석의 계층적 프로세스
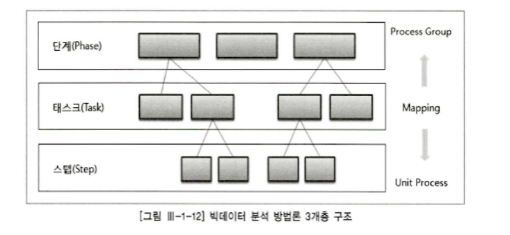
1단계(Phase): 프로세스 그룹을 통하여 완성된 단계별 산출물이 생성된다. 각 단계는 기준선으로 설정되어 관리되어야 하며 버전 관리 등을 통해 통제가 이루어진다.
2단계(Task): 각 단계는 여러 테스트로 구성된다. 각 테스트는 단계를 구성하는 단위의 활동이며 물리적 또는 논리적 단위로 품질 검토의 항목이 될 수 있다.
3단계(Step): WBS의 워크 패키지에 해당되고, 입력자료(Input), 처리도구(Process&Tool), 출력자료(Output)로 구성된 단위 프로세스이다.
빅데이터 분석방법론
분석기획(Planning): 비즈니스 도메인과 문제점 인식하고 분석 계획 및 프로젝트 수행계획을 수립하는 단계
데이터 준비(Preparing): 비즈니스 요구사항과 데이터 분석에 대한 필요한 원천 데이터를 정의하고 준비하는 단계
데이터 분석(Analyzing):원천 데이터를 분석용 데이터 셋으로 편성하고 다양한 분석 기법과 알고리즘을 이용하여 데이터를 분석하는 단계. 분석 단계를 수행하는 과정에서 추가적인 데이터 확보가 필요한 경우 데이터 준비 단계로 피드백하여 두 단계를 반복 진행
시스템 구현(Developing): 분석 기획에 맞는 모델을 도출하고 이를 운영 중인 가동 시스템에 적용하거나 시스템 개발을 위한 사전 검증으로 프로토타입 시스템을 구현
평가 및 전개(Lesson Learned): 데이터 분석 및 시스템 구현 단계를 수행한 후, 프로젝트의 성과를 평가하고 정리하거나 모델의 발전 계획을 수립하여 차기 분석 기획으로 전달하고 프로젝트 종료하는 단계
분석기획(Planning)
1) 비즈니스 이해 및 범위 설정
| 데이터 정의 |
내부 업무 매뉴얼과 관련 자료, 외부 관련 비즈니스 자료를 조사하고 향후 프로젝트 진행을 위한 방향을 설정 입력: 업무메뉴얼, 전문가 지식, 빅데이터 분석대상, 도메인 관련 자료 프로세스 및 도구: 자료 수집 및 비즈니스 이해 출력자료: 비즈니스 이해 및 도메인 문제점 |
| 프로젝트 범위 설정 |
빅데이터 분석 프로젝트에 대한 이해와 프로젝트 목적에 부합하는 범위를 설정하고 프로젝트 범위 정의서인 SOW를 작성 입력: 중장기 계획서, 빅데이터 분석 프로젝트 지시서, 비즈니스 이해 및 도메인 문제점 프로세스 및 도구: 자료 수집 및 비즈니스 이해, 프로젝트 범위 정의서 작성절차 출력자료: 프로젝트 범위 정의서(SOW) |
2) 프로젝트 정의 및 수립
| 데이터분석 프로젝트 정의 |
프로제트 목표 및 KPI, 목표 수준 등을 구체화하여 상세 프로젝트 정의서를 작성하고 프로젝트 목표를 명확화 하기 위한 모델 운영 이미지 및 평가 기준을 설정 입력: 프로젝트 범위 정의서(SOW), 빅데이터 분서 프로젝트 지시서 프로세스 및 도구: 프로젝트 목표 구체화, 모델 운영 이미지 설계 출력자료: 프로젝트 정의서, 모델 운영 이미지 설계서, 모델 평가 기준 |
| 프로젝트 수행 계획 수립 |
프로젝트의 목적 및 배경, 기대효과, 수행방법, 일정 및 추친조직, 프로젝트 관리 방안을 작성하고 WBS는 프로젝트 산출물 위주로 작성되어 프로젝트의 범위를 명확하게 함 입력: 프로젝트 범위 정의서(SOW), 모델 운영 이미지 설계서, 모델 평가 기준 프로세스 및 도구: 프로젝트 범위 정의서(SOW), WBS 작성 출력자료: 프로젝트 수행계획서, WBS |
3) 프로젝트 위험 계획 수립
| 데이터분석 위험식별 |
앞서 진행된 프로젝트 산출물과 정리 자료를 참조하고 전문가의 판단을 활용해 프로젝트를 진행하며 발생한 위험을 식별. 식별된 위험은 위험의 영향도, 빈도, 발생가능성에 따라 위험의 우선순위 설정 입력: 프로젝트 범위 정의서(SOW), 프로젝트 수행 계획서, 선행 프로젝트 산출물 및 정리자료 프로세스 및 도구: 위험 식별 절차, 위험영향도 및 발생 가능성 분석, 위험 우선순위 판단 출력자료: 식별된 위험 목록 |
| 프로젝트 수행계획 수립 |
식별된 위험은 상세한 정량적, 정성적 분석을 통해 위험 대응방안을 수립. 예상되는 위험에 대해 회피, 전이, 완화, 수용으로 구분하여 위험 관리 계획서 작성 입력: 식별된 위험 목록, 프로젝트 범위 정의서(SOW), 프로젝트 수행 계획서 프로세스 및 도구: 위험 정량적 분석, 위험 정성적 분석 출력자료: 위험관리 계획서 |
데이터 준비(Preparing)
1) 필요 데이터 정의
| 데이터 정의 |
시스템, 데이터베이스, 파일, 문서 등의 다양한 데이터 소스로부터 분석에 필요한 데이터를 정의 입력: 프로젝트 수행 계획서, 시스템 설계서, ERD, 메타데이터 정의서, 문서자료 프로세스 및 도구: 내외부 데이터 정의, 정형, 비정형, 반정형 데이터 정의서 출력자료: 데이터 정의서 |
| 데이터 획득방안 수립 |
내외부 다양한 데이터 소스로부터 정형, 비정형, 반정형 데이터 수집하기 위한 구체적 방안 수립. 내부 데이터 획득에는 부서간 업무 협조와 개인정보 보호 및 정보보안과 관련한 문제점을 사전 검토. 외부 데이터 획득은 다양한 인터페이스 및 법적 문제점을 고려하여 상세한 데이터 획득 계획 수립 입력: 데이터 정의서, 시스템 설계서 ERD, 메타데이터 정의서, 문서자료, 데이터 구입 프로세스 및 도구: 데이터 획득 방안 수립 출력자료: 데이터 획득 계획서 |
2) 데이터 스토어 설계
| 정형데이터 스토어 설계 |
정형데이터는 일반적으로 관계형 데이터베이스인 RDBMS를 사용하고 데이터의 효율적인 저장과 활용을 위하여 데이터스토어의 논리적, 물리적 설계를 구분하여 설계 입력: 데이터 정의서, 데이터 획득 계획서 프로세스 및 도구: 데이터베이스 논리, 물리 설게, 데이터 매핑 출력자료: 정형 데이터 스토어 설계서, 데이터 매핑 정의서 |
| 비정형 데이터 스토어 설계 |
하둡, NoSQL 등을 이용하여 비정형 또는 반정형 데이터를 저장하기 위한 논리적, 물리적 데이터 스토어 설계 입력: 데이터 정의서, 데이터 획득 계획서 프로세스 및 도구: 데이터 비정형, 반정형 데이터 논리, 물리 설계 출력 자료: 비정형 데이터 스토어 설계서, 데이터 매핑 정의서 |
3) 데이터 수집 및 정합성 점검
| 데이터 수집 및 저장 |
크롤링 등 데이터 수집을 위한 ETL 등과 같은 다양한 도구와 API, 스크립트 프로그램 등을 이용하여 데이터를 수집하고, 수집한 데이터를 설계돈 데이터 스토어에 저장 입력: 데이터정의서, 데이터 획득 계획서, 데이터 스토어 설계서 프로세스 및 도구: 데이터 크롤링 도구, ETL 도구, 데이터 수집 스크립트 출력자료: 수집된 분석용 데이터 |
| 데이터 정합성 점검 |
데이터 스토어의 품질 점검을 통하여 데이터의 정합성을 확보하고 데이터 품질 개선이 필요한 부분에 대하여 보완 작업을 함 입력: 수집된 분석용 데이터 프로세스 및 도구: 데이터 품질확인, 정합성 점검 리스트 출력도구: 정합성 점검 보고서 |
데이터 분석(Analyzing)
1) 분석용 데이터 준비
| 비즈니스 확인 |
비즈니스 이해, 도메인 문제점 인식, 프로젝트 정의 등을 이용하여 프로젝트의 목표를 정확하게 인식. 세부적인 비즈니스 룰을 파악하고 분석에 필요한 데이터의 범위 확인 입력: 프로젝트 정의서, 프로젝트 수행계획서, 데이터 정의서, 데이터 스토어 프로세스 및 도구: 프로젝트 목표 확인, 비즈니스 룰 확인 출력자료: 비즈니스 룰, 분석에 필요한 데이터 범위 |
| 분석용 데이터 셋 준비 |
데이터 스토어로부터 분석에 필요한 정형, 비정형 데이터 추출. 필요시 적절한 가공을 통하여 분석도구 입력 자료로 사용될 수 있도록 편성. 추출된 데이터는 데이너베이스나 구조화된 형태로 구성하고 필요시 준석을 위한 작업공간과 전사차원의 데이터 스토어로 분리 입력: 데이터 정의서, 데이터 스토어 프로세스 및 도구: 데이터 선정, 데이터 변환, ETL도구출력도구: 분석용 데이터 셋 |
2) 텍스트 분석
| 텍스트 데이터 확인 및 추출 |
데이터 스토어에서 필요한 텍스트 데이터 추출 입력: 비정형 데이터 스토어 프로세스 및 도구: 분석용 텍스트 데이터 확인, 텍스트 데이터 추출 출력도구: 분석용 텍스트 데이터 |
| 텍스트 데이터 분석 |
추출된 텍스트 데이터를 분석도구로 적재하여 다양한 기법을 분석하고 모델을 구축. 텍스트 분석을 위해 용어사전을 사전에 확보하고 업무 도메인에 맞도록 작성. 구축된 모델은 시각화 도구를 이용하여 모델의 의미 전달을 명확하게 함 입력: 분석용 텍스트 데이터, 용어사전(유의어 사전, 불용어 사전등) 프로세스 및 도구: 분류 체게 설계, 형태소 분석, 키워드 도출, 토픽 분석, 감성 분석, 의견 분석, 네트워크 분석 출력도구: 텍스트 분석 보고서 |
3) 탐색적 분석
| 탐색적 데이터 분석 |
다양한 관점별로 기초 통계량(평균, 분산, 표준편차, 최댓값, 최소값)을 산출하고, 데이터 분포와 변수간의 관계 등 데이터 자체 특성 및 데이터의 통계적 특성을 이해하고 모델링을 위한 기초자료로 활용 입력: 분석용 데이터 셋 프로세스 및 도구: EDA 도구, 통계 분석, 연관성 분석, 데이터 분포 확인 출력 도구: 데이터 탐색 보고서 |
| 데이터 시각화 |
탐색적 데이터 분석을 위한 도구로 활용. 그러나 모델의 시스템화를 위한 시각화를 목적으로 활용할 경우 시각화 기획, 시각화 설계, 시각화 구현 등 별도의 프로세스에 따라 진행. 탐색적 데이터 분석을 진행하면 수행된 데이터 시각화는 모델링 또는 향후 시스템 구현을 위한 사용자 인터페이스 또는 프로토타입으로 활용될 수도 있음 입력: 분석용 데이터 셋 프로세스 및 도구: 시각화 도구, 시각화 패키지, 인포그래픽, 시각화 방법론 출력도구: 데이터 시각화 보고서 |
4) 모델링
| 데이터 분할 |
모델의 과적합과 일반화를 위하여 분석용 데이터 셋을 모델 개발을 위한 훈련용 데이터와 모델의 검증력을 테스트 하기 위한 테스트용 데이터로 분할. 모델에 적용하는 기법에 따라 데이터 분할 또는 검증횟수, 생성모델 개수 등 설정 입력: 분석용 데이터 셋 프로세스 및 도구: 데이터 분할 패키지 출력도구: 훈련용 데이터, 테스트용 데이터 |
| 데이터 모델링 |
기계학습 등을 이용한 데이터 모델리은 훈련용 데이터를 활용하여 분류, 에측, 군집 등의 모델을 만들어 가동중인 운영 시스템에 적용. 필요시 비정형 데이터 분석결과를 통합적으로 활용하여 프로젝트 목적에 맞는 통합모델을 수행 입력: 분석용 데이터 셋프 로세스 및 도구: 통계 모델링 기법, 기계학습, 모델 테스트 출력도구: 모델링 결과 보고서 |
| 모델적용 및 운영방안 |
모델을 가동중인 운영 시스템에 적용하기 위해서는 모델에 대한 상세한 알고리즘 설명서 작성이 필요. 알고리즘 설명서는 시스템 구현단계에서 중요한 입력자료로 활용되므로 필요시 의사코드 수준의 상세한 작성이 필요. 또한 모델의 안정적 운영을 모니터링하는 방안도 수립 입력: 모델링 결과 보고서프 로세스 및 도구: 모니터링 방안 수립, 알고리즘 설명서 작성 출력도구: 알고리즘 설명서, 모니터링 방안 |
5) 모델 평가 및 검증
| 모델 평가 | 프로젝트 정의서의 모델 평가 기준에 따라 모델을 객관적으로 평가하고 품질관리 차원에서 모델 평가 프로세스를 진행함. 모델 평가를 위해 모델 결과 보고서 내의 알고리즘을 파악하고 테스트용데이터나 필요시 모델 검증을 위한 별도의 데이터를 활용 입력: 모델링 결과 보고서, 평가용 데이터 프로세스 및 도구: 모델 평가, 모델 품질관리, 모델 개선작업 출력작업: 모델 평가 보고서 |
| 모델 검증 | 모델의 실적용성을 검증하기 위해 검증용 데이터를 이용해 모델 검증 작업을 실시하고 모델링 검증 보고서를 작성. 검증용 데이터는 모델 개발 및 평가에 활용된 훈련용이나 테스트용 데이터가 아닌 실 운영용 데이터를 확보하여 모델의 품질을 최종 검증 입력: 모델링 결과 보고서, 모델 평가 보고서, 검증용 데이터 프로세스 및 도구: 모델 검증 출력작업: 모델 검증 보고서 |
시스템 구현(Developing)
1) 설계 및 구현
| 시스템 분석 및 설계 |
가동중인 시스템을 분석하고 알고리즘 설명서에 근거하여 응용 시스템 구축 설계 프로세스를 진행. 시스템 분석과 설계는 사용중인 정보시스템 개발 방법론을 커스터이징하여 적용할 수 있음 입력: 알고리즘 설명서, 운영중인 시스템 설계서 프로세스 및 도구: 정보 시스템 개발 방법론 출력자료: 시스템 분석 및 설계서 |
| 시스템 구현 |
시스템 분석 및 설계서에 따라 BI 패키지를 활용하거나 새롭게 시스템을 구축하거나 가동중인 운영시스템의 커스터마이징 등을 통하여 설계된 모델 구현 입력: 시스템 분석 및 설계서, 알고리즘 설명서 프로세스 및 도구: 시스템 통합 개발 도구, 프로그램 언어, 패키지 출력자료: 구현 시스템 |
2) 시스템 테스트 및 운영
| 시스템 테스트 |
구축된 시스템의 검증을 위하여 단위 테스트, 통합 테스트, 시스템 테스트 등을 실시. 시스템 테스트는 품질 관리차원에서 진행함으로써 적용된 시스템의 객관성과 완전성 확보 입력: 구현 시스템, 시스템 테스트 계획서 프로세스 및 도구: 품질관리 활동 출력자료: 시스템 테스트 결과 보고서 |
| 시스템 운영 계획 |
구현된 시스템을 지속적으로 활용하기 위해 시스템 운영자, 사용자를 대상으로 필요한 교육 실시하고 시스템 운영 계획을 수립 입력: 시스템 분석 및 설계서, 구현 시스템 프로세스 및 도구: 운영계획 수립, 운영자 및 사용자 교육 출력자료: 운영자 매뉴얼, 사용자 매뉴얼, 시스템 운영 계획서 |
평가 및 전개(Lesson Learned)
1) 모델 발전 계획 수립
| 모델 발전 계획 |
개발된 모델의 지소적인 운영과 기능 향상을 휘나 발전계획을 상세하게 수립하여 모델의 계속성 확보 입력: 구현시스템, 프로젝트 산출물 프로세스 및 도구: 모델 발전 계획 수립 출력자료: 모델 발전 계획서 |
2) 프로젝트 평가 및 보고
| 프로젝트 성과평가 |
프로젝트의 정량적 성과와 정성적 성과로 나누어 성과 평가서를 작성 입력: 프로젝트 산출물, 품질관리 산출물, 프로젝트 정의서, 프로젝트 수행계획서 프로세스 및 도구: 프로젝트 평가 기준, 프로젝트정량적 평가, 프로젝트 정성적 평가 출력자료: 프로젝트 성과 보고서 |
| 프로젝트 종료 |
프로젝트 진행과정의 모든 산출물 및 프로세스를 지식자산화하고 최종 보고서를 작성하여 의사소통 절차에 따라 보고하고 종료 입력: 프로젝트 산출물, 품질관리 산출물, 프로젝트 정의서, 프로젝트 수행 계획서, 프로젝트 성과 계획서 프로세스 및 도구: 프로젝트 지식 자산화 작업, 프로젝트 종료 출력자료: 프로젝트 최종 보고서 |
'Study > ADSP' 카테고리의 다른 글
| [ADsP] 2과목 데이터 분석 기획 - 2장 분석 마스터 플랜 (0) | 2022.03.03 |
|---|---|
| [ADsP] 2과목 데이터 분석 기획 - 1장 데이터 분석기획의 이해 (2) (0) | 2022.03.02 |
| [ADsP] 1과목 데이터 이해 - 3장 가치 창조를 위한 데이터 사이언스와 젼략 인사이트 (1) | 2022.03.01 |
| [ADsP] 1과목 데이터 이해 - 2장 데이터의 가치와 미래 (0) | 2022.03.01 |
| [ADsP] 1과목 데이터 이해 - 1장 데이터의 이해 (0) | 2022.02.28 |