728x90
groupby란?
연산자를 사용하여 집단, 그룹별로 데이터를 집계, 요약하는 방법
전체 데이터를 그룹 별로 나누고 (split), 각 그룹별로 집계함수를 적용(apply) 한후, 그룹별 집계 결과를 하나로 합치는(combine) 단계를 거치게 된다.
예시
아래와 같은 DataFrame이 있다고 가정한다.
df=pd.DataFrame({
'key':['A','A','B','B','B','C','C','D'],
'key1':['a','a','a','a','b','a','b','a'],
'MIN':[1,2,2,3,5,NaN,8,5],
'MAX':[3,4,4,4,8,4,10,7]})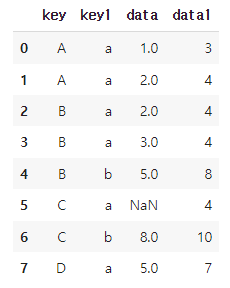
1. 특정 column 기준으로 그룹화
groupby 함수를 사용하여 특정 column을 그룹화 한 후, 평균 / 최소값 / 최대값 / 개수 등을 구할 수 있다.단, NaN값은 제외하고 계산하게 된다.
- 평균: mean() / 최소값: min() / 최대값: max() / 개수: count() / 중간값: median()
- 표준편차: std() / 분산: var() / 특정백분위: quantile()
- 전반적인 지표: describe()
df[['key','data','data1']].groupby(['key']).mean()
여러 개의 column을 기준으로도 구할 수 있다.
df.groupby(['key','key1']).min()
index를 사용하고 싶지 않은 경우, as_index=False 옵션을 사용하면 아래와 같은 결과가 나온다.
df.groupby(['key','key1'],as_index=False).mean()
2. agg 함수 사용하기
agg 함수를 사용하면 그룹조건이 여러개가 되는 경우가 있고 한번에 여러 컬럼을 다르게 연산 할 수 있다.
또한 문자열 같은 경우, join 하여 한 줄에 표기 할 수 있다.
df.groupby('key').agg({'key1':','.join,'data':'min','data1':'mean'})
중복을 제거하고 싶으면 아래와 같이 set을 사용할 수 있다.
df.groupby('key').agg({'key1':lambda x: ','.join(set(x))})
728x90
'Programming > PYTHON' 카테고리의 다른 글
| [Python] Flask로 웹사이트 만들기 (1) (0) | 2022.10.10 |
|---|---|
| [Python] pandas 사용하기 (3) - concat / merge / join (0) | 2022.08.15 |
| [Python] pandas 사용하기 (2) - 문자열 다루기 (0) | 2022.08.11 |
| [Python] pandas 사용하기 (1) - 기본적인 pandas 사용방법 (0) | 2022.03.03 |
| [Python] win32com (pywin32) 사용하기 (2) - 셀 꾸미기 (0) | 2022.02.19 |