pandas 라이브러리란?
panel datas(패널 자료)의 약자로 DB처럼 테이블 형식의 데이터를 쉽게 처리할 수 있는 라이브러리이다. 데이터가 테이블 형식으로 이루어진 경우가 많아 데이터 분석 시 자주 사용하게 될 Python 패키지이다.
pandas 설치하기
pip install pandaspip 명령어를 사용하여 pandas 라이브러리를 설치한다.
pandas 모듈 가져오기
import numpy as np
import pandas as pdpandas 라이브러리를 pd라는 약자로 불러와 사용될 수 있도록 선언한다.
numpy는 벡터와 행렬연산에 있어 편리한 기능을 제공하는 라이브러리인데, pandas와 함께 데이터 분석에 사용하면 효과적이다.
Object 생성하기

pandas에는 2가지 오브젝트가 존재한다.
Series: 1차원 데이터와 각 데이터의 위치 정보를 담는 Index로 구성
Dataframe: 2차원 데이터와 Index와 Column으로 구성
Series 생성하기
pd.Series(data=None, index=None)pandas.Series를 통해 Series를 생성할 수 있다.
data: 딕셔너리(Dictionary, dict), ndarray, 스칼라 값
index: 입력된 인덱스는 축(행) 레이블의 리스트를 입력받는다. 입력하지 않을 경우 자동으로 생성된다. (1,2,3...)
DataFrame 생성하기
pd.DataFrame(data,index=None, columns=columns)pandas.DataFrame를 통해 DataFrame를 생성할 수 있다.
data: 딕셔너리(Dictionary, dict)에 1차원 ndarray, list, series, dictionary와 같은 자료형이 포함되는 경우, 하나의 Series, 2차원 ndarray, 리스트의 리스트, 구조체 ndarray 혹은 record ndarray, 또다른 DataFrame
index: 입력된 인덱스는 축 레이블의 리스트를 입력받는다. 입력하지 않을 경우 자동으로 생성된다. (1,2,3...)
columns: 입력된 column은 열의 레이블의 리스트를 입력받는다.
Viewing Data(데이터 보기)
### Data 일부 내용을 볼 경우(기본 5줄)
df.head()
df.tail(3)
### index나 column을 확인할 경우
df.index
df.columns
### 값들을 확인할 경우
df.valueshead(), tail()의 함수로 처음과 끝의 일부 데이터의 일부분을 볼 수 있다.(기본 5개, 숫자 입력시 해당 row 까지만) 데이터가 큰 경우에 데이터가 어떤식으로 구성되어 있는지 확인할 때 자주 사용한다.
index나 column의 내용을 확인 할 경우에 .index와 .column을 사용하고 값을 확인하고 싶으면 .values를 사용한다.

Selection(데이터 선택하기)
특정 행과 열 선택하기
특정 column을 가져오고 싶은 경우 대괄호 안에 특정 column의 이름을 입력한다. ex) df['A']
여러 column을 가져오고 싶은 경우, 하나의 column 명 대신 대괄호를 쓰고 여러 column을 입력하면 된다. ex) df[['A','C']]
특정 index를 가져오고 싶은 경우에도 대괄호 안에 특정 index를 입력한다. 0~2와같이 행 범위를 가져오고 싶은 경우 ":"를 사용한다. ex) df[0:2]

loc과 iloc 사용하기
loc: 컬럼명을 직접 적거나 특정 조건식을 써줌으로써 사람이 읽기 좋은 방법으로 데이터를 접근한다.
lloc: 컴퓨터가 읽기 좋은 밥법(숫자)로 데이터가 있는 위치를 접근한다.

위의 예외 같이 df.loc[0,'A']와 df.iloc[0,0]은 같다.
그리고 iloc과 loc을 사용할 때, 행이나 열 선택 인자에 ':'을 사용하여 행 또는 열 전체를 가져올 수도 있다.

조건을 이용하여 선택하기
특정한 열의 값들을 기준으로 조건을 만들어 해당 조건에 만족하는 행들만 선택할 수 있는 방법이 있다. 또한 각 값을 기준으로 조건을 만들 수도 있다.

데이터 변경하기
선택했던 데이터 프레임의 특정 값들을 다른 값으로 변경할 수 있다. 위에서 선택한 영역에 대한 값을 변경하거나, 특정 조건에 만족하는 값들만 변경할 수 있다.

Missing Data(결측치)
pandas는 주로 np.nan을 사용하여 결측 데이터(데이터가 없는 것)을 나타낸다.
결측 데이터 삭제하기
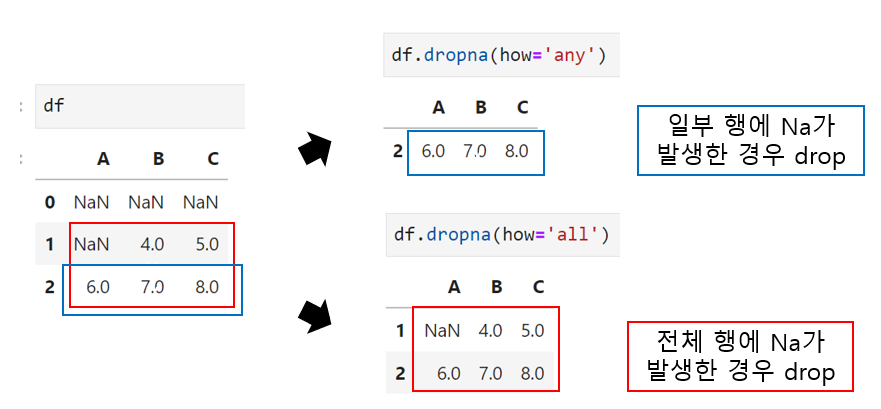
df.dropna(how='any') ## 결측값이 하나라도 있는 경우 삭제
df.dropna(how='all') ## 전체가 결측값일 경우에 삭제dropna()을 사용하여 결측값을 삭제할 수 있다. how='any'일 경우 결측값이 하나라도 있는 경우에 삭제하고, how='all'인 경우에는 전체가 결측값일 경우에만 삭제한다.
결측 데이터 값 입력하기
df1.fillna(0) ## 결측값에 특정값 입력fillna()를 사용하여 결측 데이터의 값을 입력할 수 있다.

결측값 위치 확인 하기
pd.isnull()로 결측데이터 여부를 True/False 형태로 확인할 수 있다.

[참고 링크]
https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html
10 minutes to pandas — pandas 1.4.1 documentation
Note While standard Python / NumPy expressions for selecting and setting are intuitive and come in handy for interactive work, for production code, we recommend the optimized pandas data access methods, .at, .iat, .loc and .iloc.
pandas.pydata.org
'Programming > PYTHON' 카테고리의 다른 글
| [Python] pandas 사용하기 (3) - concat / merge / join (0) | 2022.08.15 |
|---|---|
| [Python] pandas 사용하기 (2) - 문자열 다루기 (0) | 2022.08.11 |
| [Python] win32com (pywin32) 사용하기 (2) - 셀 꾸미기 (0) | 2022.02.19 |
| [Python] win32com (pywin32) 사용하기 (1) (0) | 2022.02.18 |
| [Python] openpyxl로 엑셀 다루기 (2) - style 적용하기 (0) | 2022.02.17 |