정리 내용은 [2022 ADsP 데이터 분석 준전문가]책을 기반으로 작성하였습니다.
2022 ADsP 데이터 분석 준전문가 - 교보문고
본 도서는 한국데이터베이스진흥원에서 실시하고 있는 『데이터 분석 전문가(ADP)』 자격증과 『데이터 분석 준전문가(ADsP)』 자격증을 준비하는 수험생들을 위한 도서이다. 2014년 4월 이후 시행
www.kyobobook.co.kr
1. R소개
1. 데이터 분석 도구 현황
R의 탐색
R은 오픈소스 프로그램으로 통게, 데이터 마이닝과 그래프를 위한 언어
다양한 최근 통계분석과 마이닝 기능을 제공
세계적으로 많은 사용자들이 다양한 예제를 공유
다양한 기능을 지원하는 많은 패키지가 수시로 업데이트
분석도구의 비교
| SAS | SPSS | 오픈소스 R | |
| 프로그램 비용 | 유료, 고가 | 유료, 고가 | 오픈소스 |
| 설치 용량 | 대용량 | 대용량 | 모듈화로 간단 |
| 다양한 모듈 지원 및 비용 |
별도 구매 | 별도 구매 | 오픈소스 |
| 최근 알고리즘 및 기술 반영 |
느림 | 다소느림 | 매우빠름 |
| 학습자료 입수의 편의성 | 유료 도서 위주 | 유료 도서 위주 | 공개 논문 및 자료 많음 |
| 질의를 위한 공개 커뮤니티 |
NA | NA | 매우활발 |
R의 특징
오픈소스 프로그램 / 그래픽과 성능 / 시스템 데이터 저장 방식 / 모든 운영 체제 / 표준 플랫폼 / 객체지향 언어이며 함수형 언어
R스튜디오
오픈소스이며 다양한 운영체계를 지원
R스튜디오는 메모리에 변수가 어떻게 되어있는지 타입이 무엇인지를 볼 수 있고 스크립트 관리와 도큐먼테이션이 편리
코딩을 해야 하는 부담이 있으나 스크립트용 프로그래밍이므로 어렵지 않게 자동화가 가능
래틀은 GUI가 패키지와 긴밀하게 결합되어 있어 정해진 기능만 사용 가능해 업그레이드가 제대로 되지 않으면 통합성에 문제가 발생할 수 있다.
2. R 기초
1. 통계 패키지 R
R 스튜디오 구성화면
스크립트: R 명령어를 입력하는 창
워크스페이스: 할당된 변수와 데이터가 나타나는 창
콘솔: 명령문을 실행하는 창
설치된 패키지, plot, help를 보여주는 창
패키지
R 함수와 데이터 및 컴파일된 코드의 모임
패키지 불러들이기
1) 하드디스크: R을 설치하거나 업데이트를 통해 설치
2) 웹: 2014년 CRAN. 저장소에는 약 5000개 의 유용한 패키지가 자동 설치 / install.packages(”AID”)
3) 패키지 도움말
- library(help=AID): 다운로드된 AID 패키지의 help 다큐먼트를 보여준다.
- help(package=AID): 웹을 통한 AID 패키지의 다큐먼트가 보여준다.
프로그램 파일 실행
| R 코드 | 기능 / 내용 |
| source('파일명') | 스크립트로 프로그래밍된 파일 실행하기오른쪽 방향키 |
| sink(file, append, split) 함수 |
R 코드 실행결과를 특정 파일에서 출력 file: 출력할 파일명append: 파일에 결과를 엎어쓰거나 추가해서 출력(디폴트: False / 덮어쓰기) split: 출력파일에만 출력하거나 콘솔창에 출력(디폴트: False / 파일에만 실행결과 출력) |
| pdf() 함수 | 그래픽 출력을 .pdf로 지정[ex] pdf(”A_out.pdf”) |
| dev.off() 함수 | 프로그램 파일 닫기 |
배치 모드 기능
배치 모드: 배치모드 방식은 사용자와 인터렉션이 필요하지 않은 방식으로 매일 돌아가야 한느 시스템에서 프로세스를 자동화할 때 유용하다.
배치 파일 실행 명령: $ CMD BATCH batch.R이라는 윈도우 도스창에서 실행한다.
Path 지정: 내 컴퓨터 오른쪽 마우스 클릭->속성->고급 시스템 설정-> 환경변수 클릭-> 변수명 path 클릭-> R프로그램의 실행파일 위치를 찾아서 추가->저장
배치파일 실행: 윈도우 창의 batch.R 실행파일이 있는 위치에서 R CMD BATCH batch.R 실행
2. 변수와 벡터 생성
R 데이터 유형과 객체
숫자: integer, double
논리값: True(T), False(F)
문자: “a”, “abc”
3. R 기초 중에 기초
출력하기
print(): 출력 형식을 지정할 필요 없음, 한 번에 하나의 객체만 출력
cat(): 여러 항목을 묶어서 연결된 결과로 출력, 복합적 데이터 구조(행렬, list 등)을 출력할 수 없음
커맨드 프롬프트에 변수나 표현식을 입력
[ex] print(a), print(”A”,”B”,”C”)
변수에 값 할당하기(대입 연산자)
<-, <<-, =, ->
변수 목록보기
Is(), Is.str()
변수 삭제하기
rm()
rm(list=ls(): 모든 변수를 삭제할 때 사용
백터 생성하기
c(): 벡터의 원소 중 하나라도 문자가 있으면 모든 원소의 모드는 문자형태로 변환됨
R함수 정의하기
fuction(매개변수 1, 매겨변수2,,,,,베개 변수 n){expr1, expr2,,,,exprn}
지역변수: 단순히 값을 대입하기만 하면 지역변수로 생성되고, 함수가 종료되면 지역변수는 삭제됨
조건문: if문 / 반복문 for, while, repeat 문 / 전역 변수:<<- 를 사용하여 전역 변수로 지정할 수 있지만 추천하지 않음
4. R 프로그램 소개
데이터 할당
a<-1, a=1
화면 프린트
a, print(a) =>프린트 함수
결합
x<-c(1,2,3,4) / x<-c(6.25,3.14,5.18) / x<-c(”fee”,”fie”,”fun”) / x<-c(x,y,z)
C 함수는 문자, 숫자, 논리 값, 변수를 모두 결합 가능하며 벡터와 데이터 셋을 생성 가능
수열
1:5 / 9:-2 / seq(from=0, to=20,by=2) / seq(from=0, to=20,length.out=5)
콜론, seq함수를 사용하여 시작 값~최종 값까지의 연속 숫자 생성, seq함수는 간격과 결괏값의 길이를 제한 가능

반복
rep(1,time=5) / rep(1:4, each=2), rep(c,each=2)
rep 함수는 숫자나 변수의 값들을 time 인자에 지정한 횟수만큼 반복

문자 붙이기
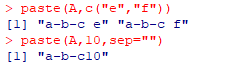
A<-paste(”a”,”b”,”c”,sep=”-”) / paste(A,c(”e”,”f”) / paste(A,10,sep=””)
문자열 추출
substr(”Bigdataanalysis”,1,4)
substr(문자열, 시작점, 끝점)함수는 문자열의 특정 부분을 추출 가능
논리 값
a<-True / a<-T / b<-False / b<-F ( T=True, F=False로 인식)
논리 연산자
==: 같다 / !=: 같지않다 / <,<=: 작다, 작거나 같다 / >,>=: 크다, 크거나 같다
벡터의 원소 선택하기
V[n]: 선택하고자 하는 자리수 / V[-n]: 제외하고자 하는 자리수 / n: 원소의 자리수, V: 벡터의 이름
5. 백터와 연산
| 연산자 우선순위 | 뜻 | 사용법 |
| [ [[ | 인덱스 | a[1] |
| $ | 요소 뽑아내기, 슬롯 뽑아내기 | a$coef |
| ^ | 지수 | 5^3 |
| -, + | 단항 마이너스와 플러스 부호 | -3, +5 |
| : | 수열 생성 | 1:10 |
| %any% | 특수 연산자 | %/%: 나눗셈 몫, %% 나눗셈 나머지, %*% 행렬의 곱 |
| * / | 곱하기, 나누기 | 3*3, 3/5 |
| +, - | 더하기, 빼기 | 3+2, 3-1 |
| ==, !=, <> , <=, >= | 비교 | 3==5 |
| ! | 논리부정 | !(3==5) |
| & | 논리 ,”and”, 단축(short-circuit) “and” | TRUE&TRUE |
| | | 논리 ,”or”, 단축(short-circuit) “or” | TRUE|TRUE |
| ~ | 식(formula) | lm(log(brain)~log(body).data=Animals) |
| ->, ->> | 오른쪽 대입 | 3->a |
| = | 대입(오른쪽을 왼쪽으로) | a=4 |
| <-, <<- | 대입(오른쪽을 왼쪽으로) | a<-4 |
| ? | 도움말 | ?lm |
6. 벡터의 기초 통계
mean(변수): 변수의 평균 산출
sum(변수): 변수의 합계 산출
median(변수): 변수의 중앙값 산출
log(변수): 변수의 로그값 산출
sd(변수): 변수의 표준편차 산출
var(변수): 변수의 분산 산출
cov(변수1, 변수2): 변수간 공분산 산출
cor(변수1, 변수2): 변수간 상관계수 산출
length(변수): 변수간 길이를 값으로 출력
7. R 프로그래밍 시 자주 하는 실수
| 기능 | 기능 / 내용 |
| 함수를 불러오고 괄호닫기 | function 함수에서의 {}, 함수의 () |
| 윈도우 파일 경로에서 역슬레시 두번씩 쓰기 | f:\dataedu\r\test.csv => f:\dataedurtest.csv 로 인식함역슬레시(\)를 두번 쓰거나, 슬레시(/)를 한번 써야함 |
| <-사이를 붙여쓰기 |  |
| 여러줄 넘어서 식을 계속 넘어갈 때 |
 |
| ==대신 =을 사용하지 말것 | ==는 비교연산자 / =은 대입연산자 |
| 1:(n+1)대신 1:n+1로 쓰지 말것 |  |
| 패키지를 불러오고 library()나 require()을 수행할 것 |
|
| 2번 써야할 것과 1번 써야 할 것을 혼돈하지 말 것 | aList[[a]] vs aList[a] / && vs & / || vs | 등 |
| 인자의 개수를 정확히 사용할 것 |  |
3. 입력과 출력
1. 데이터 분석과정
분석자가 분석 목적에 맞게 적절한 분석방법론을 선택해서 정확한 분석을 통해 통찰력을 가지고 해석함으로써 분석과정을 마치게 된다.
이렇게 데이터를 분석하기 위해서는 분석자가 분석을 위해 설계된 방향으로 데이터를 정확하게 입력받는 것에서부터 시작될 수 있다.
그리고 입력된 데이터는 다양한 전처리 작업을 거쳐 분석이 가능한 형태로 재정리됩니다. 우리는 이것을 데이터 핸들링이라고도 한다.
또한 분석된 결과를 이해하기 쉽고 잘 해석될 수 있도록 생산하는 부분이 데이터 출력이라고 할 수 있다. 출력된 결과를 보고서 형태로 정리되어 최종 의사결정자와 고객에게 전달되게 욈으로써 통계 분석과정은 종료된다고 할 수 있다.
2. R에서의 데이터 입력과 출력
R에서 처리할 수 있는 데이터 타입은 아래와 같다.
R에서 다룰 수 있는 파일 타입: Tab-delimited text, Comma-spearated text, Excel file, JSON file, HTML/XML file, Database, (Other) Statistical SW file
| 기능 | 기능 / 내용 |
| 키보드로 데이터를 입력 |
1) 데이터 양이 적어 직접 입력 - c():combine 함수 2) 데이터 편집기 활용하기: 빈데이터프레임 생성->편집기를 불러와 서 편집 & 데이터프레임에 엎어 씌우기 |
| 출력할 내용의 자리수 정의 |
R 부동 소수점 표현: 7자리 표시 print(pi,digits=num) / cat(format(pi,,digits=num),”\n”) / options(digits=num) |
| 파일에 출력하기 |
cat(”출력할 내용”,”변수”,”\n”,file=”파일이름”,append=T) sink(”파일이름”) ...출력할내용... sink() |
| 파일 목록보기 | list.files() / list.files(recursive=T,all.files=T) |
| Cannot Open File 해결하기 |
파일위치: c:\data\sample.txt -> R에서는 c”datasample.txt라고 인식함 [방법1] 역슬래쉬를 슬래쉬로 바꾼다. c:/data/sample.txt [방법2] 역슬래쉬를 두 번 쓴다. c:\\data\\sample.txt |
| 고정자리수 데이터파일 읽기 |
read.fwf(”파일이름”,widths=c(w1,w2,...,wn)) |
| 테이블로 된 데이터파일 읽기 (변수구분자 포함) |
read.table(”파일이름”,sep=”구분자”) [주의1] 주소, 이름, 성 등의 텍스트를 요인으로 인식함 read.table(”파일이름”,sep=”구분자”,stringsASFactor=F) [주의2] 결측치를 NA가 아닌 다른 문자로 표현할 때 read.table(”파일이름”,sep=”구분자”,na.strings=”.”) [주의3] 파일의 첫 행을 변수명으로 인식하고자 할 때 read.table(”파일이름”,sep=”구분자”,header=T) |
| CSV데이터파일 읽기 (변수구분자 쉼표) |
read.csv(”파일이름”,header=T) [주의1] 주소, 이름, 성 등의 텍스트를 요인으로 인식함read.csv(”파일이름”,header=T, as.is=T) |
| CSV 데이터파일로 출력 (변수구분자 쉼표) |
write.csv(행렬, 또는 데이터 프레임, ”파일이름”,row.names=F) [주의1] 1행이 변수명으로 자동인식하지만 변수명이 아닐 경우 write.csv(dfm, ”파일이름”,col.names=F) [주의2] 1열에 레코드 번호를 자동 생성하지만 레코드 번호를 생성하지 않을 경우 write.csv(dfm, ”파일이름”,row.names=F) |
| 웹에서 데이터파일을 읽어올 때 (변수구분자 쉼표) |
read.csv(”http://www.example.com/download/data.csv”)read.table(”http://www.example.com/download/data.txt”) what=numeric(0): 토큰을 숫자로 해석 / what=integer(0): 토큰을 정수로 해석 what=complex(0): 토큰을 복소수로 해석 / what=character(0): 토큰을 문자로 해석 what=logical(0): 토큰을 논리값으로 해석 |
| html에서 테이블 읽어올 때 |
library(XML) url<-'http://www.example.com/data/table.html' t<-raedHTMLTable(url) |
| 복잡한 구조의 파일 (웹테이블) 읽어오기 |
lines<-readLines(”a.txt”,n=num) token<-scan(”a.txt”,what=numeric(0)) token<-scan(”a.txt”,what=list(v1=character(0),v2=numeric(0))) token<-scan(”a.txt”, what=list(v1=character(0), v2=numeric(0), n=num, nlines=num, skip=num, na.strings=list)) |
4. 데이터 구조와 데이터 프레임
1. 벡터
벡터들은 동질적이다: 한 벡터의 모든 원소는 같은 자료형 또는 같은 모드를 가진다.
벡터는 위치로 인덱스 된다: v[2]는 v벡터의 2번째 원소이다.
벡터는 인덱스를 통해 여러 개의 원소로 구성된 하위 벡터를 반환할 수 있다: v[c(2,3)]은 v벡터의 2번째, 3번째로 구성된 하위 벡터이다.
벡터 원소들은 이름을 가질 수 있다.

2. 리스트
리스트는 이질적이다: 여러 자료형의 원소들이 포함될 수 있다.
리스트는 위치로 인덱스 된다: L[[2]]는 L리스트의 2번째 원소이다.
리스트는 하위 리스트를 추출할 수 있다: L[c(2,3)]은 L리스트의 2번째, 3번째 원소로 이루어진 하위 리스트이다.
리스트의 원소들은 이름을 가질 수 있다: L[[”Moe”]]와 L$Moe는 둘 다 Moe라는 이름의 원소를 지칭한다.
3. R에서의 자료 형태
| 객체 | 예시 | 모드 |
| 숫자 | 3.1415 | 수치형(numeric) |
| 숫자 벡터 | c(2,3,4,5,6) | 수치형(numeric) |
| 문자열 | “Tom” | 문자형(character) |
| 문자열 벡터 | c(”Tom”,”Yoon”,”Kim”) | 문자형(character) |
| 요인 | factor(c(”A”,”B”,”C”)) | 수치형(numeric) |
| 리스트 | list(”Tom”,”Yoon”,”Kim”) | 리스트(list) |
| 데이터프레임 | data.frame(x=1:3, y=c(”Tom”,”Yoon”,”Kim”)) | 리스트(list) |
| 함수 | 함수(function) |
4. 데이터 프레임
데이터 프레임은 강력하고 유연한 구조. SAS의 데이터셋을 모방해서 만들어진다.
데이터 프레임의 리스트의 원소는 벡터 또는 요인이다.
그 벡터와 요인은 데이터프레임의 열이다.
벡터와 요인은 동일한 길이이다.
데이터 프레임은 표 형태의 데이터 구조이며 각 열은 서로 다른 데이터 형식을 가질 수 있다.
열에는 이름이 있어야 한다.
[ex] 데이터 프레임의 원소에 대한 접근 방법: b[1]; b[”empno”] / b[[i]];b[[”empno”]] / b$empno
5. 그 밖의 데이터 구조들
| 객체 | 설명 |
| 단일값 | R 원소가 하나인 벡터로 인식 처리 |
| 행렬 | R 에서는 차원을 가진 벡터로 인식 |
| 배열 | 행렬에 3차원 또는 n차원까지 확장된 상태. 주어진 벡터에 더 많은 차원을 부여하여 배열 생성 |
| 요인 | 벡터처럼 생겼지만, R에서는 벡터에 있는 고유값 정보를 얻어내는데, 이 고유값들을 요인의 수준이라고 함. 요인은 두가지 주된 사용처로 범형 변수, 집단 분류가 있다. |
6. 벡터, 리스트, 행렬 다루기
행렬은 R에서 차원을 가진 벡터이며, 텍스트 마이닝과 소셜 네트워크 분석 등에 활용한다.
재활용 규칙: 길이가 서로 다른 두 벡터에 대한 연산을 할 때, R은 짧은 벡터의 처음으로 돌아가 연산이 끝날 때까지 원소들을 재활용한다.
| a<-seq(1,6) | b<-seq(7,9) | a+b | cbind(a,b) |
| 1 | 7 | 8 | 1 7 |
| 2 | 8 | 10 | 2 8 |
| 3 | 9 | 12 | 3 9 |
| 4 | 11 | 4 7 | |
| 5 | 13 | 5 8 | |
| 6 | 15 | 6 9 |
| 기능 | 코드 및 비고 |
| 벡터에 데이터 추가 | v<-c(v,newitem) / v[length(v)+1]<-newitem |
| 벡터에 데이터 삽입 | append(vec, newvalues, after=n) |
| 요인 생성 | f<-factor(v), v: 문자열 또는 정수 벡터f<-factor(v, levels) |
| 여러 벡터를 합쳐 하나의 벡터와 요인으로 만들기 |
comb<-stack(list(v1=v1,v2=v2,v3=v3)) |
| 벡터 내 값 조회 | v[c(1,3,5,7)]: 벡터 내 1,3,5,7번째 값 조회 v[-c(2,4)]: 벡터 내 2,4번째 값을 제외하고 조회 |
| 리스트 | list(숫자, 문자, 함수): 리스트 함수의 인자로는 숫자, 문자, 함수가 포함 |
| 리스트 생성하기 | L<-list(x,y,z)L<-list(valuename1=data, valuename2=data, valuename3=data) L<-list(valuename1=vec, valuename2=vec, valuename3=vec) |
| 리스트 원소 선택 | L[[n]]: n번째 원소 / L[c(n1,n2,n3...nk)]: 목록 |
| 이름으로 리스트 선택 | L[[”name”]], L$name |
| 리스트 원소 제거 | L[[”name”]]<-NULL |
| NULL원소 리스트에서 제거 | L[sapply(L,is.null)]<-NULL / L[L==o]<-NULL / L[is.na(L)]<-NULL |
| 행렬 | matrix(data, 행수, 열수), a<-matrix(data,2,3), d<-matrix(0,4,5), e<-matrix(1:20,4,5) data 대신 숫자를 입력하면 행렬의 값이 동일한 수치값 부여 |
| 차원 | dim(행렬), dim(a): a행렬의 차원은 2행,3열 |
| 대각 | diag(행렬), diag(b): b행렬의 대각선 ㄱ밧 반환 |
| 전치 | t(행렬), t(a): a행렬의 전치행렬을 반환 |
| 역 | slove(matrix) |
| 행렬의 곱 | 행렬 %*% t(행렬), a%*% t(a) |
| 행 이름 부여 | rownames(a)<-c(”행이름1”,”행이름2”,”행이름3”) |
| 열 이름 부여 | colnamems(a)<-c(”행이름1”,”행이름2”,”행이름3”) |
| 행렬의 연산 +,- | f+f, f-f: 행렬간의 덧셈, 뺄셈 / f+1, f-1: 행렬 상수간 덧셈, 뺄셈 |
| 행렬의 연산 * | f%*%f: 행렬간의 곱 / f*3: 행렬 상수 간의 곱 |
| 행렬에서 행, 열 선택하기 | vec<-matrix[1,] / vec<-matrix[,3] |
7. 데이터 프레임
| 기능 | 코드 및 비고 |
| 데이터프레임 | data.frame(벡터,벡터,벡터): 벡터들로 데이터 셋 생성 |
| 레코드 생성 | new<-data.frame(a=1,b=2,c=3,d=”a”)레코드 생성시 숫자, 문자를 함께 사용 가능 |
| 열 데이터(변수)로 데이터 프레임 만들기 |
dfm<-data.frame(v1,v2,v3,f1,f2)dfm<-as.data.frame(list.of.vectors) |
| 데이터셋 행 결합 | rbind(dfrm1, dfrm2) / newdata <- rbind(data, row)두 데이터프레임을 행으로 결합 |
| 데이터셋 열 결합 | cbind(dfrm1, dfrm2) / newdata <- cbind(data, col)두 데이터프레임을 행으로 결합 |
| 데이터 프레임 할당 | N=1,000,000dftm<-data.frame(dosage=numeric(N),lab=character(N), response=numeric(N)) |
| 데이터프레임 조회 | [방법1] dfrm[dfrm$gender=”m”]: 데이터셋 내 성별이 남성만 조회 [방법2] dfrm[dfrm$변수1>4 & dfrm$변수2>5, c(변수3, 변수4)]: 데이터셋의 변수1과 변수2의 조건에 만족하는 레코드 변수3과 변수4만 조회 [방법3] dfrm[grep(”문자”, dfrm$변수1, ignore.case=T), c(”변수3”, ”변수4”)]: 데이터셋의 변수1내 “문자”가 들어있는 케이스들의 변수2, 변수3값을 조회 |
| 데이터셋 조회 | subset(dfrm, select=변수, subset=변수>조건) 데이터셋의 특정변수의 값이 조건에 맞는 변수셋 조회, subset은 벡터와 리스트에서도 선택 가능 |
| 데이터 선택 | lst1[[2]], lst1[2], lst1[2,], lst1[,2] lst1[[”name”]], lst1$name lst1[c(”name1”, “name2”, ..., “namek”)] |
| 데이터 병합 | merge(df1, df2, by=”df1과 df2의 공통 열 이름”): 공통변수로 데이터셋 병합 |
| 열 네임 조회 | colnames(변수): 변수의 속성들을 조회 |
| 행, 열 선택 | subset(dfm, select=열이름) subset(dfm, select=c(열이름1, 열이름2,...,열이름n))subset(dfm, select=열이름,subset(조건)) 열이름에 “” 표시 안함, 조건에 맞는 행의 열 자료만 선택 |
| 이름으로 열 제거 | subset(dfm, select=-”열이름”) |
| 열이름 바꾸기 | colnames(dfm)<-newnames |
| NA 있는행 삭제 | NA_cleaning<-na.omit(dfm) |
| 데이터 프레임 두개 합치기 |
열: cbind_dfm <- cbind(dfm1, dfm2) 행: rbind_dfm<- rbind(dfm1, dfm2) [유의사항1] cbind 행의 개수가 동일해야함-recycling Rule [유의사항2] rbind 열의 개수와 열의 이름이 동일해야 함 |
| 두개 데이터 프레임을 동일한 변수 기분으로 합치기 |
merge(dfm1, dfm2,by=”T_name”) merge(dfm1, dfm2,by=”T_name”, all=T) |
8. 자료형 데이터 구조 반환
| 기능 | 코드 |
| 데이터프레임의 내용에 쉽게 접근하기 |
with(dfm, expr) / attach(dfm) / detach(dfm) |
| 자료형 변환하기 | as.character() / as.complex() / as.numeric() 또는 as.double() as.inteager() / as.logical() |
| 데이터구조변환하기 | as.data.frame() / as.list() / as.matrix() / as.verctor() |
9. 데이터 구조 변경
| 기능 | 코드 |
| 벡터->리스트 | as.list(vec) |
| 벡터->행렬 | 1행짜리 행렬: cbind(vec) 또는 as.matrix(vec) 1열짜리 행렬: rbind(vec) / nxm 행렬: matrix(vec, n, m) |
| 벡터->데이터프레임 | 1열짜리 데이터프레임: as.data.frame(vec) 1행짜리 데이텨프레임: as.data.frame(rbind(vec)) |
| 리스트->벡터 | unlist(lst) |
| 리스트->행렬 | 1열짜리 행렬: as.matrix(lst) / 1행짜리 행렬: as.matrix(rbind(lst)) nxm 행렬: matrix(lst, n, m) |
| 리스트->데이터프레임 | 목록 원소들이 데이터의 열이면: as.data.frame(lst) 리스트 원소들이 데이터의 행이면: rbin(obs[[1]], obs[[2]]) |
| 행렬->벡터 | as.vector(mat) |
| 행렬->리스트 | as.list(mat) |
| 행렬->데이터프레임 | as.data.frame(mat) |
| 데이터프레임->벡터 | 1열짜리 데이터프레임: dfm[[1]] or dfm[[,1]] 1행짜리 데이터프레임: dfm[1,] |
| 데이터프레임->리스트 | as.list(dfm) |
| 데이터프레임->행렬 | as.matrix(dfm) |
10. 벡터의 기본 연산
| 기능 | 코드 |
| 벡터 연산 | 벡터1+벡터2(덧셈연산) / 벡터1-벡터2(뻴셈연산) / 벡터1*벡터2(곱셈연산) / 벡터1^벡터2(승수연산) |
| 함수 적용 | sapply(변수, 연산함수) / sapply(a,log)연산 및 적용함수를 통해 변수에 적용 |
| 파일 저장 | write.csv(변수이름, “파일이름.csv”) write.csv(변수이름, file=“파일이름.Rdata”): R파일로 저장 |
| 파일 읽기 | read.csv(”파일이름.csv”) |
| 파일 불러오기 | load(”파일 R”) / source(”a.R”): R파일 불러오기 |
| 데이터 삭제 | rm(변수): 변수를 메모리에서 삭제rm(list=Is(all=True)): 모든 변수를 메모리에서 삭제 |
11. 그 외에 간단한 함수
| 기능 | 코드 |
| 데이터 불러오기 | data(): R에 내장된 데이터셋 리스트를 보여줌. / data(데이터셋): 데이셋을 불러들임 |
| 데이터셋 요약 | summary(데이터셋): 데이터셋 변수 내용을 요약 |
| 데이터셋 조회 | head(데이터셋): 6개 레코드까지 데이터 조회 |
| 패키지 설치 | install.packages(”패키지 명”) |
| 패키지 불러오기 | library(”패키지 명”) |
| 작업종료 | q() |
| 워킹디렉토리 지정 | setwd(”~/”): R데이터, 파일을 로드하거나 저장할 때 워킹 디렉토리를 저장 |
5. 데이터 변형
1. 주요 코드
| 기능 | 코드 |
| 요인으로 집단 정의 | v<-c(24, 23, 52, 46, 75, 25) / w<-c(87, 86, 92, 84, 77, 66) f<-factor(c(”A”,”A”,”B”,”B”,”C”,”A”)) |
| 벡터를 여러 집단으로 분할 (벡터의 길이만 같으면 됨) |
groups<-split(v,f) / groups<-split(w,f) groups<-unstack(dta.frame(v,f)) 두 함수 모두 벡터로 된 리스트를 반환 |
| 데이터프레임을 여러집단으로 분할 |
MASS 패키지, Cars93 데이터셋 활용 library(MASS) sp<-split(Cars93$MPG.city, Cars93$Origin) median(sp[[1]]) |
| 리스트의 각 원소에 ㄲ ㅍ함수 적용 |
lapply(결과를 리스트 형태로 반환) list<-lapply(l, func) sapply(결과를 벡터 또는 행렬로 반환) vec<-sapply(l,function) |
| 행렬에 함수 적용 | m<-apply(mat, 1, func) / m<-apply(mat, 2, func) |
| 데이터프레임에 함수 적용 | dfm<-lapply(dfm, func)dfm<-sapply(dfm, func) dfm<-apply(dfm, func): 데이터프레임이 동질적인 경우만(모든문자, 숫자)활용가능데이터프레임을 행렬로 변환 후 함수 적용 |
| 대용량 데이터의 함수 적용 |
cors <- sapply(dfm, cor, y=targetVariable) mask <- (rank(-abs(cors)) <= 10) best.pred <- dfm[, mask] lm(targetVariable ~ bes.pred) 많은 변수가 있는 데이터에서의 다중회귀 분석 1. 데이터프레임에서 타겟 변수를 정함 2. 타겟변수와 상관계수를 구한다. 3. 상관계수가 높은 상위 10개의 변수를 입력변수로 선정 4. 타겟변수와 입력변수로 다쥥회귀분석을 실시한다. |
| 집단별 함수 적용 | tapply(vec, factor, func) 데이터가 집단(factors)에 속해 있을 때 합계/평ㄲ균 구하기 |
| 행집단 함수 적용 | by(drm, factor, fucnc): 요인별 선형회구선 구하기 model(dfm, factor,function(df) Im(종속변수~독립변수1+독립변수2+...독립변수 k, data=df)) |
| 병렬 벡터, 리스트들 함수 적용 |
mapply(factor, v1, …, vk) mapply(factor, list1, …, list k) |
2. 문자열 날짜 다루기
| 기능 | 코드 |
| 문자열 길이 | nchar("단어"): 단어나 문장 또는 백터 내 원소의 문자열 길이 반화 [주의] length(vec): 문자열의 길이가 아닌 벡터 길이반환 |
| 문자열 연결 | paste("word1", "word2", sep="-") paste("the pi is approximately”, pi)paste(vec, “loves me”, collapse=”, and”) |
| 하위문자열 추출 | substr("statistics", 1, 4): 문자열의 1번째에서 4자리 추출 |
| 구분자로 문자열 추출 | strsplit(문자열, 구분자) |
| 하위 문자열 대체 | sub(old, new, string) gsub(old, new, string) |
| 쌍별 조합 | mat <- outer(문자열1, 문자열2, paste, sep="") |
| 날짜변환 | Sys.Date( ): 현재 날짜 반환 / as.Data(): 날짜 객체 반환 format(Sys.Date(), format=%m%d%y) |
| 날짜조회 | format(Sys.Date(), "%a") 요일조회 / format(Sys.Date(), "%b") 축약된 월조회 format(Sys.Date(), "%B") 전체 월조회 / format(Sys.Date(), "%d") 두자리 숫자의 일조회 format(Sys.Date(), "%m") 두자리 숫자의 월조회 format(Sys.Date(),"%y") 두자리 숫자의 연도조회 format(Sys.Date(), "%Y") 네자리 숫자의 연도조회 |
| 날짜 일부 추출 | d <- as.Date("2014-12-25") p <- as.POSIXlt(d) p$yday start <- as.Date("2014-12-01") end <- as.Date("2014-12-25") seq(from=start, to=end, by=1) |
벡터: 하나의 스칼라 값 또는 하나 이상의 스칼라 원소들의 갖는 단순한 형태의 집합으로 한 벡터의 모든 원소는 같은 자료형(수자 또는 문자)로 구성 벡터는 행렬 구조로 나타나지 않는다.
Inf: 무한대 / NaN: Not a Number / dim: 행렬의 차원 / NA: 결측값
rbind: row 합치기 / cbind: 칼럼 합치기
install.packages("패키지명")->library(패키지명)
merge / subset
'Study > ADSP' 카테고리의 다른 글
| [ADsP] 3과목 데이터 분석 - 4장 통계분석 (1) (0) | 2022.03.07 |
|---|---|
| [ADsP] 3과목 데이터 분석 - 3장 데이터마트 (0) | 2022.03.06 |
| [ADsP] 3과목 데이터 분석 - 1장 데이터 분석 개요 (0) | 2022.03.04 |
| [ADsP] 2과목 데이터 분석 기획 - 2장 분석 마스터 플랜 (0) | 2022.03.03 |
| [ADsP] 2과목 데이터 분석 기획 - 1장 데이터 분석기획의 이해 (2) (0) | 2022.03.02 |