1. 슈퍼타입/서브타입 모델의 성능 고려 방법
슈퍼/서브타입 데이터 모델 개요
Extended ER 모델이라고 부름. 최근 데이터모델링을 할 때 자주 쓰이는 모델링 방법. 분석단계에서 많이 쓰임
업무를 구성하는 데이터 특징을 공통과 차이점의 특징을 고려하여 효과적으로 표현
공통의 부분을 슈퍼타입으로 모델링 / 공통의 부분에서 상속받아 차이가 있는 속성에 대해서는 서브엔터티로 구분
슈퍼타입/서브타입 데이터 모델의 장점
1) 업무의 모습 정확히 표현
2) 물리적인 데이터 모델로 변환할 때 선택의 폭을 넓힐 수 있음
2. 슈퍼/서브타입 데이터 모델의 변환
변환 기준
데이터의 양, 트랜잭션 유형
슈퍼/서브타입에 대한 변환을 잘못하면 발생하는 경우의 수
성능이 저하 발생함. 이는 트랜잭션 특성을 고려하지 않고 테이블이 설계되었기 때문
1) 트랜잭션은 항상 일괄로 처리하는데 테이블은 개별로 유지되어 Union 연산에 의해 성능이 저하
2) 트랜잭션은 항상 서브타입 개별로 처리하는데 테이블은 하나로 통합되어 있어 불필요하게 많은 양의 데이터 때문에 성능이 저하된다.
3) 트랜잭션은 항상 슈퍼+서브타입을 공통으로 처리하는데 개별로 유지거나, 하나의 테이블로 집약 되어있어 성능이 저하
슈퍼/서브 타입 데이터 모델의 변환기술
| 변환 기술 | 설명 |
| 1:1 타입 (OneToOne type) |
개별로 처리하는 트랜잭션에 대해 개별 테이블 구성, 슈퍼타입과 서브타입 각각 필요한 속성과 유형에 적합한 데이터만 가지도록 분리하여 1:1 관계를 갖도록 함 |
| 슈퍼/서브 타입 (Plus type) |
슈퍼타입과 서브타입을 공통으로 처리하는 트랜잭션에 대해 슈퍼타입과 서브타입 각각의 테이블 구성 |
| All in One 타입 (Single type) |
일괄 처리하는 트랜잭션에 대해 단일 테이블 구성 |
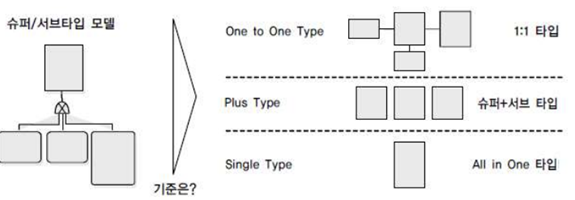
슈퍼/서브타입 데이터 모델의 변환 타입 비교
| 1:1 타입 | 슈퍼/서브 타입 | All in One 타입 | |
| 특징 | 개별 테이블 유지 | 슈퍼/서브 타입 테이블 구성 | 단일 테이블 구성 |
| 트랜잭션 유형 | 개별 처리 | 슈퍼/서브 타입 공통 처리 | 일괄 처리 |
| 확장성 | 좋음 (테이블 추가 용이) | 보통 | 나쁨 |
| 조인 성능 | 나쁨(조인 많이 필요) | 나쁨(조인 많이 필요) | 좋음 |
| I/O 성능 | 좋음 | 좋음 | 나쁨 (항상 전체 데이터 조회) |
| 관리용이성 | 나쁨 | 나쁨 | 좋음 |
3. 인덱스 특성을 고려한 PK/FK 데이터 베이스 성능 향상
PK/FK 칼럼 순서와 성능 개요
일반적으로 데이터베이스 테이블에서는 균형잡힌 트리구조의 B*-Tree 구조를 많이 사용한다.
일반적으로 프로젝트에서는 PK / FK 칼럼 순서의 중요성을 인지하지 못한 채로 데이터 모델링이 되어 있는 그 상태대로 바로 DDL을 생성함으로써 데이터베이스 데이터처리 성능에 문제를 유발하는 경우가 발생
PK/FK 칼럼 순서 조절을 통한 성능 향상: 등호 조건이나 BETWEEN 조건이 걸리는 칼럼을 앞으로 이동 (여러 조건이 있을 경우 등호 조건이 걸리는 칼럼을 선두로 이동)
인덱스 특성을 고려한 PK/FK DB 성능 향상: 물리적인 테이블에 FK 제약을 걸어 인덱스를 생성
PK순서를 지정할 때, 여러 속성이 하나의 인덱스로 구성되어 있을 때 앞쪽에 위치한 속성 값이 비교자로 있어야 좋은 효율 (앞쪽에 위치한 속성 값이 가급적 '=' 아니면 최소한의 범위 'BETWEEN' 이나 '<>'가 들어와야 앞에서부터 데이터를 거르고, 걸러진 데이터를 뒤져보는 형태로 작동하므로 성능의 효과가 높아짐)
FK에 대해서는 반드시 인덱스를 생성하도록 하고, 인덱스 컬럼 순서도 조회 조건 고려해서 가장 효율적으로 순서 생성
PK 칼럼의 순서를 조정하지 않으면 성능이 저하 이유
PK의 순서를 인덱스 특징에 맞게 고려하지 않고 바로 그대로 생성하게 되면, 테이블에 접근하는 트랜잭션의 특징에 효율적이지 않은 인덱스가 생성되어 있으므로 인덱스의 범위를 넓게 이용하거나 Full Scan을 유발하게 되어 성능이 저하 발생
'Study > SQLD' 카테고리의 다른 글
| 2-1장 SQL 기본 - 1절 관계형 데이터베이스 개요 (0) | 2022.06.20 |
|---|---|
| 1-2장 데이터 모델과 성능 - 6절 분산 데이터베이스와 성능 (0) | 2022.06.19 |
| 1-2장 데이터 모델과 성능 - 4절 대량 데이터에 따른 성능 (0) | 2022.06.17 |
| 1-2장 데이터 모델과 성능 - 3절 반정규화와 성능 (0) | 2022.06.16 |
| 1-2 장 데이터 모델과 성능 - 2절 정규화와 성능 (0) | 2022.06.15 |